



Intro
Livet som teknisk SEO kan være meget tempofyldt. En pagespeed-audit den ene uge, internationale overvejelser den næste, indholdsbeskæring derefter osv. osv.
Tekniske SEO'er kan blive så optaget af en vigtig (eller vegansk) opgave, at de ofte overser de mindre rettelser, som kan have stor betydning for din organiske præstation.
Det er ikke tekniske SEO-sølvkugler, men anbefalinger, som du ved, at du burde rette op på, men som du aldrig gør.
Derfor vil jeg dele nogle af mine yndlings "åh ja, det havde jeg glemt at tjekke" problemer, når jeg gennemgår et websted.
Regel om omdirigering med store bogstaver
Enhver teknisk SEO, der er sit salt værd, kender de åbenlyse regler for omdirigering og ved, hvor de skal anvendes, f.eks. http til https-sider, trailing slash til non-trailing slash osv.
Men hvornår har du sidst kontrolleret, at alle siders URL'er tvinger små bogstaver frem?
Da URL er den unikke identifikator for en webside, betragtes www.example.com/category og www.example.com/Category derfor som forskellige sider, selv om indholdet er det samme.
Alt-i-en-platformen til effektiv SEO
Bag enhver succesfuld virksomhed ligger en stærk SEO-kampagne. Men med utallige optimeringsværktøjer og -teknikker at vælge imellem kan det være svært at vide, hvor man skal starte. Nå, frygt ikke mere, for jeg har lige det, der kan hjælpe dig. Jeg præsenterer Ranktracker alt-i-en platformen til effektiv SEO
Vi har endelig åbnet for gratis registrering til Ranktracker!
Opret en gratis kontoEller logge ind med dine legitimationsoplysninger
Dette kan skabe problemer med duplicate content i søgemaskinerne, så det er nødvendigt at bruge små bogstaver i URL'er.
Problemer med paginering
Hvis det websted, du administrerer, har kategoripaginering, er URL-mønstret ofte som følger:
www.example.com/mattresses/memory-foam-mattresses?p=1 www.example.com/mattresses/memory-foam-mattresses?p=2 www.example.com/mattresses/memory-foam-mattresses?p=3I dette eksempel er ?p=1-siden imidlertid en kopi af den kanoniske www.example.com/mattresses/memory-foam-mattresses-side.
Derfor bør denne ?p=1-duplikat omdirigeres 301 til siden www.example.com/mattresses/memory-foam-mattresses, og alle interne links bør opdateres, så de afspejler ændringen.
Et andet problem, der er let at glemme, er problemet med kanoniske tags. Ofte refererer ?p=2, ?p=3-siderne til den første side i deres canonical tags.
Ved at henvise til den første side på alle sider med sidetal fortæller du søgemaskinerne, at siderne er de samme som den første side, hvilket betyder, at crawlere ikke kan gennemsøge de andre sider eller følge links til produkterne fra dem. Gør dem selvrefererende!
Brug Meta noindex Tag i stedet for robots.txt
Jeg ser meddelelsen "Der er ingen oplysninger til rådighed for denne side" HELE tiden, når jeg kigger på indekserede sider i Google:
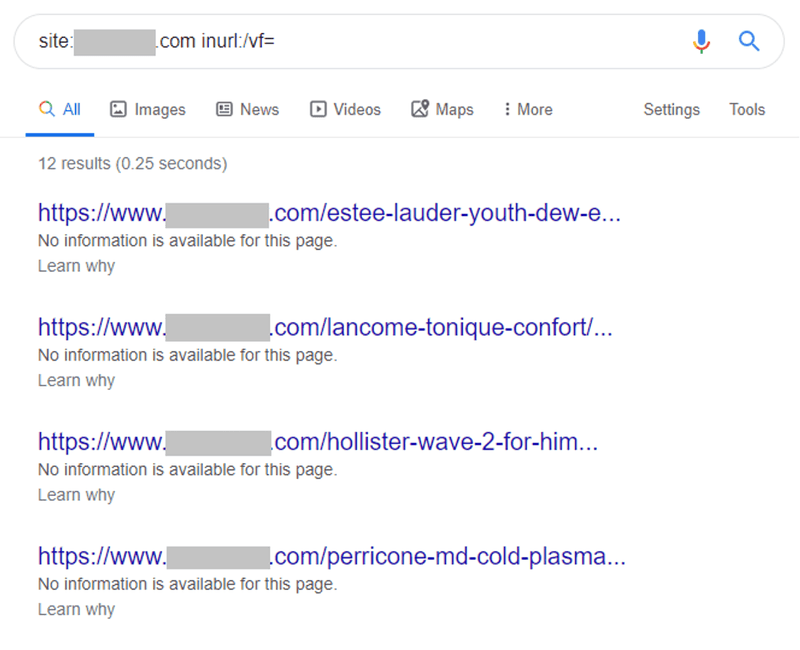
Det skyldes, at webmasteren har forsøgt at fjerne en side fra indekset ved at tilføje et disallow-direktiv mod den i robots.txt.
Alt-i-en-platformen til effektiv SEO
Bag enhver succesfuld virksomhed ligger en stærk SEO-kampagne. Men med utallige optimeringsværktøjer og -teknikker at vælge imellem kan det være svært at vide, hvor man skal starte. Nå, frygt ikke mere, for jeg har lige det, der kan hjælpe dig. Jeg præsenterer Ranktracker alt-i-en platformen til effektiv SEO
Vi har endelig åbnet for gratis registrering til Ranktracker!
Opret en gratis kontoEller logge ind med dine legitimationsoplysninger
Disse sider kan dog stadig findes via søgninger, så det er bedre at fjerne dem fra robots.txt og tilføje et noindex-tag mellem HEAD-tagsene på de sider, der ikke skal indekseres.
Fjern Meta nofollow fra udvalgte sider
Dette gælder naturligvis ikke for alle sider, der har et nofollow-tag, men mange nofollow-tags tilføjes ofte ved en fejltagelse sammen med et noindex-tag. Hvis du fjerner nofollow-anvisningen, forbedrer du flowet af link-autoritet og crawler-adgang rundt på webstedet.
Selv om søgemaskinerne måske ikke behøver at indeksere disse sider, kan sider, som de linker til, blive indekseret, og derfor bør linkene følges.
Dev Site i indekset
Jeg elsker at finde et staging-websted, der stadig er indekseret, når jeg gennemgår en potentiel kundes websted. Det viser en mangel på udviklerpleje og kan være en god måde at få kunden på din side tidligt i et forhold.
Den bedste måde at blokere et testmiljø fra at blive indekseret på er at beskytte det med en adgangskode eller begrænse det baseret på et IP-område.
Nogle hurtige metoder til at tjekke, om dit websted bliver indekseret i Google, er med avancerede søgeoperatorer som f.eks:
- Websted:dev.example.com - Websted:staging.example.com - Websted:prod.example.com - Websted:example.com inurl:test - Websted:example.com -inurl:www.Gennemgå dit XML Sitemap
XML sitemaps bliver ofte glemt, hvis de ikke genereres automatisk. Her er 3 hurtige kontroller, der tilsammen tager mindre end 5 minutter:
Tjek 1 - Er der linket til XML Sitemap i robots.txt?
Søgemaskinecrawlere vil altid lede efter en robots.txt-fil i rodmappen på et websted. Derfor skal du tilføje et link til dit XML-sitemap i robots.txt-filen for at henvise alle større søgemaskiner til dens placering.
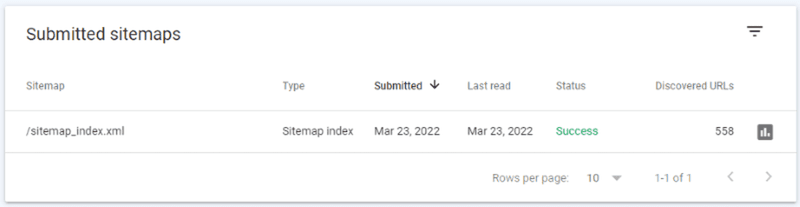
Tjek 2 - Er XML-sitemapet blevet tilføjet til Google Search Console?
Ved at indsende XML-sitemaps til Google Search Console sikrer du, at Google kan finde og gennemsøge dem. Når de er indsendt, kan du se, om Google kan finde dine side-URL'er:
Tjek 3 - Er der nogen fejl i XML sitemap?
URL'er i sitemaps bør ikke videresende eller returnere fejl - alle sider bør returnere en 200 OK-statuskode. Søgemaskinerne kan ignorere sitemaps helt, hvis de indeholder for mange fejl.
Du kan se, om der er fejl i dit sitemap ved at kigge i Google Search Console, når XML-sitemapet er blevet indsendt. Alternativt kan du crawle et XML-sitemap i Screaming Frog ved at vælge Mode > List > Upload > Download XML-sitemap.
Fjern gammelt indhold fra indekset
Hvornår har du sidst kigget på dit daterede indhold, f.eks. konkurrencesider for konkurrencer, der sluttede i 2017?
Alt-i-en-platformen til effektiv SEO
Bag enhver succesfuld virksomhed ligger en stærk SEO-kampagne. Men med utallige optimeringsværktøjer og -teknikker at vælge imellem kan det være svært at vide, hvor man skal starte. Nå, frygt ikke mere, for jeg har lige det, der kan hjælpe dig. Jeg præsenterer Ranktracker alt-i-en platformen til effektiv SEO
Vi har endelig åbnet for gratis registrering til Ranktracker!
Opret en gratis kontoEller logge ind med dine legitimationsoplysninger
En gennemgang af hvilket indhold der indekseres i Google kan føre til tekniske SEO-fordele, f.eks. forbedret crawling og indeksering, så det er et vigtigt område at overveje.
Hvis der f.eks. er hundredvis af forældede blogindlæg, der indekseres, kan søgemaskinerne spilde deres crawlbudget på at besøge disse sider, når de kunne behandle mere vigtige sider.
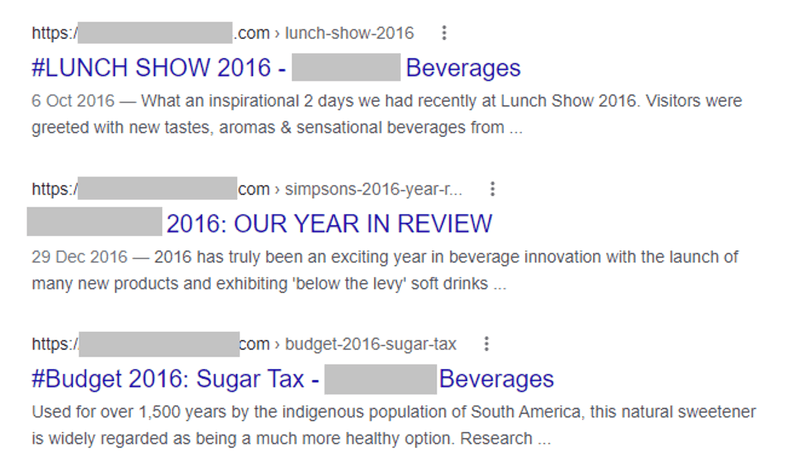
Jeg kan godt lide at finde disse daterede blogindlæg med avancerede søgeoperatorer. Nogle af mine favoritter omfatter:
- Site:example.com inurl:jul - Site:example.com inurl:konkurrence - Site:example.com inurl:pris - Site:example.com inurl:august - Site:example.com inurl:september - Site:example.com inurl:2016 - Site:example.com inurl:2017 - Etc.
