



Intro
The life of a technical SEO can be very fast-paced. A pagespeed audit one week, international considerations the next, content pruning after that, etc. etc.
Technical SEOs can get so lost in a meaty (or vegan) task, that they often overlook the smaller fixes which can have a big impact on your organic performance.
These aren’t technical SEO silver bullets, these are recommendations that you know you should fix but never do.
Therefore, I’m going to share some of my favourite “oh yeah, forgot to check that” issues when auditing a website.
Uppercase redirect rule
Any Tech SEO worth their salt will know about the obvious redirect rules and where they should be applied e.g. http to https pages, trailing slash to non-trailing slash etc.
However, when was the last time you checked that all page URLs force the lowercase?
As URL is the unique identifier for a webpage, therefore www.example.com/category and www.example.com/Category are considered different pages, even though the content is the same.
The All-in-One Platform for Effective SEO
Behind every successful business is a strong SEO campaign. But with countless optimization tools and techniques out there to choose from, it can be hard to know where to start. Well, fear no more, cause I've got just the thing to help. Presenting the Ranktracker all-in-one platform for effective SEO
We have finally opened registration to Ranktracker absolutely free!
Create a free accountOr Sign in using your credentials
This can create duplicate content issues within search engines, so lowercase URLs should be forced.
Pagination problems
If the website you manage has category pagination, then the URL pattern is often as follows:
www.example.com/mattresses/memory-foam-mattresses?p=1
www.example.com/mattresses/memory-foam-mattresses?p=2
www.example.com/mattresses/memory-foam-mattresses?p=3
However, the ?p=1 page, is a duplicate of the canonical www.example.com/mattresses/memory-foam-mattresses page, in this example.
Therefore, this ?p=1 duplicate should be 301 redirected to the www.example.com/mattresses/memory-foam-mattresses page, with all internal links updated to reflect the change.
Another easy-to-forget pagination problem is with canonical tags, so it’s a good idea to check for any issues with a free tool like Attrock Canonical Tag Checker. Often the ?p=2, ?p=3 pages are referencing the first paginated page in their canonical tags.
Referencing the first page on all paginated pages tells search engines the pages are the same as the first page, meaning crawlers may not crawl the other pages or follow the links to the products from them. Make them self-referencing!
Use Meta noindex Tag Instead of robots.txt
I see the “No information is available for this page” message ALL THE TIME when looking at indexed pages within Google:
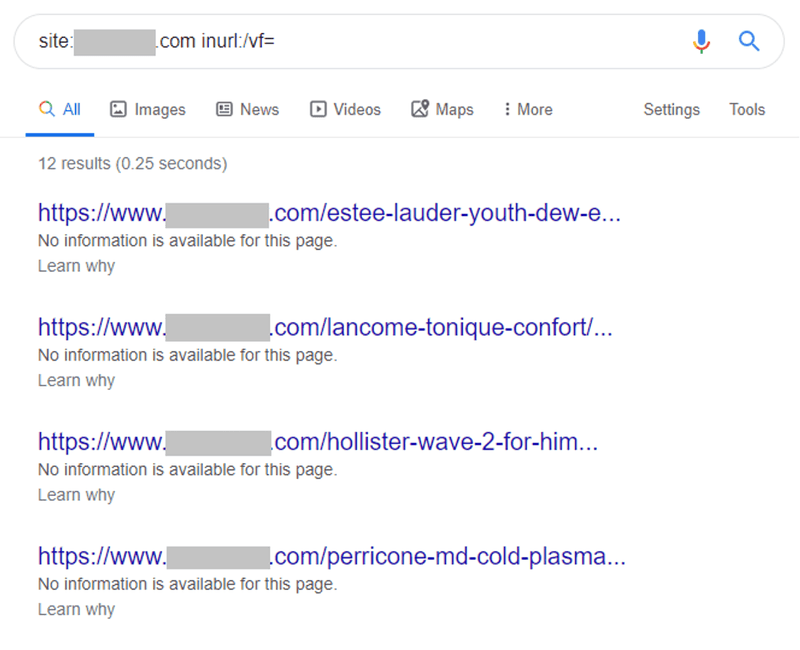
This is because the webmaster has tried to remove a page from the index by adding a disallow directive against it in the robots.txt.
The All-in-One Platform for Effective SEO
Behind every successful business is a strong SEO campaign. But with countless optimization tools and techniques out there to choose from, it can be hard to know where to start. Well, fear no more, cause I've got just the thing to help. Presenting the Ranktracker all-in-one platform for effective SEO
We have finally opened registration to Ranktracker absolutely free!
Create a free accountOr Sign in using your credentials
However, these pages can still be found via searches, so it is better to remove them from the robots.txt and add a noindex tag between the HEAD tags of the pages that shouldn’t be indexed.
Remove Meta nofollow from Select Pages
Now, this obviously doesn’t apply to all pages that have a nofollow tag, but many nofollow tags are often added with a noindex tag by mistake. Removing the nofollow instruction will improve the flow of link authority and crawler access around the site.
Although search engines might not need to index these pages, pages they link to could be indexed, therefore the links should be followed.
Dev Site in the Index
I love finding a staging site still indexed when auditing a potential client's website. It shows a lack of developer care and can be a great way to get the client on your side early in a relationship.
The best way to block a test environment from getting indexed is to password-protect or restrict based on IP range.
Some quick methods to check if your dev site is being indexed within Google is with advanced search operators such as:
- Site:dev.example.com
- Site:staging.example.com
- Site:prod.example.com
- Site:example.com inurl:test
- Site:example.com -inurl:www.
Review your XML Sitemap
XML sitemaps often get forgotten about if they aren’t automatically generated. Here are 3 quick checks that take less than 5 minutes combined:
Check 1 – Is the XML Sitemap being linked to in the robots.txt?
Search engine crawlers will always look for a robots.txt file in the root folder of a website. Therefore, adding a link to your XML sitemap within the robots.txt points all major search engines to its location.
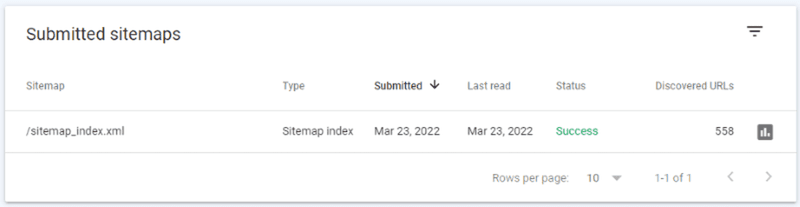
Check 2 – Has the XML Sitemap been added to Google Search Console?
Submitting XML sitemaps to Google Search Console ensures Google can find and crawl them. Once submitted, you can see if Google is successfully able to discover your page URLs:
Check 3 – Are there any errors in the XML sitemap?
URLs in sitemaps should not redirect or return errors – every page should return a 200 OK status code. Search engines may ignore sitemaps completely if they contain too many errors.
You can discover if your sitemap has any errors by looking in Google Search Console once the XML sitemap has been submitted. Alternatively, you can crawl an XML sitemap in Screaming Frog by selecting Mode > List > Upload > Download XML Sitemap.
Remove Old Content from Index
When was the last time you looked at your dated content, such as competition pages for contests that ended in 2017?
The All-in-One Platform for Effective SEO
Behind every successful business is a strong SEO campaign. But with countless optimization tools and techniques out there to choose from, it can be hard to know where to start. Well, fear no more, cause I've got just the thing to help. Presenting the Ranktracker all-in-one platform for effective SEO
We have finally opened registration to Ranktracker absolutely free!
Create a free accountOr Sign in using your credentials
Reviewing which content is being indexed within Google can lead to technical SEO benefits, like improved crawling and indexation improvements, so it is an important area to consider.
For instance, if there are hundreds of out-of-date blog posts being indexed then search engines could be wasting their crawl budget visiting these pages, when they could be processing more important pages.
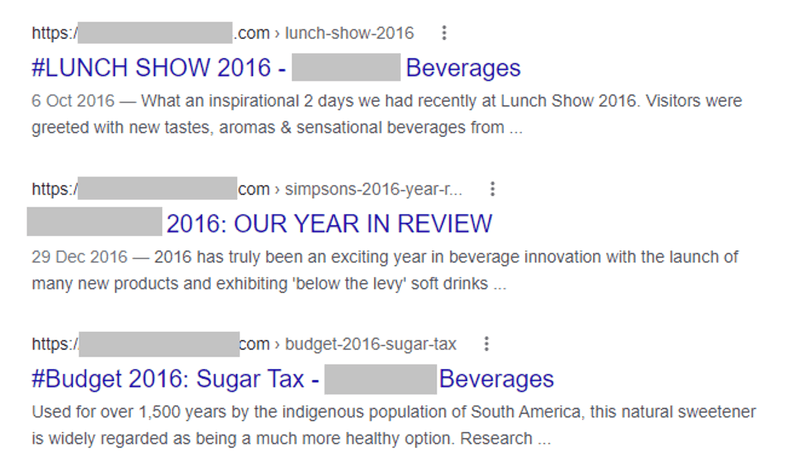
I like to find these dated blog posts with advanced search operators. Some of my favourites include:
- Site:example.com inurl:Christmas
- Site:example.com inurl:competition
- Site:example.com inurl:award
- Site:example.com inurl:august
- Site:example.com inurl:september
- Site:example.com inurl:2016
- Site:example.com inurl:2017
- Etc.

